digdag + embulk データ分析基盤の初期運用をEC2で構築

こんにちは、ベガコーポレーション データ戦略部 分析基盤エンジニア 新卒3年目の武本です。今回は今まで公開していなかった分析基盤の初期運用について紹介します。
この記事を書こうと思った背景
先日 【データ分析基盤構築】digdag+embulkをFargate運用 という記事を公開したのですが、いきなり大掛かりなものを実装するのは一苦労ですよね。なので、必要最小限でかつ安全にデータ基盤を作るにはどうすれば良いのか? ということを考えると思います。 そこで今回は初期運用をどうしていたのかという部分について紹介しようと思います。
結論
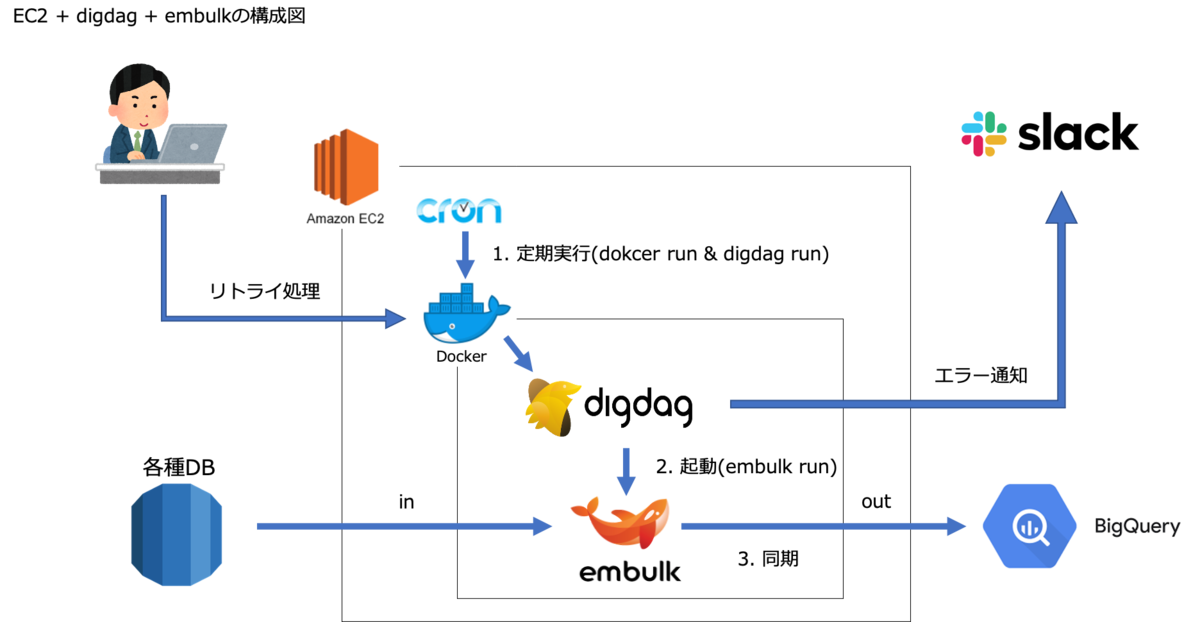 1. 定期実行Amazon Linux2のCronでdigdagを実行
1. 定期実行Amazon Linux2のCronでdigdagを実行
2. digdagからembulkを実行
これだけです。Digdag UI や Digdag Schedule などの知識を全て省いて、定期実行・フロー管理・データの同期。この3点のみを抑えることにしました。
cronとembulkだけで完結する可能性はありますがslack通知やembulkの細かい設定をするためにdigdagを採用しました。また将来的にはDigdag Serverを運用する想定もあり開発当初から初期運用という感覚でした。
Dockerを挟んでいる理由
本当に最小限の構成にするのであればDockerは必要ありません。
壊しても簡単に復旧できる環境が良いと考えたのと、将来的にECSで実行したいという思いがありDockerを採用しました。
最終的にはDigdag Serverを構築することになったので必要はなかったのですが気軽に環境を弄れるという点ではかなりメリットがありました。
デメリットとしてはログの管理が大変だったことですかね。
最小限構築のメリット・デメリット
【メリット】
- 最小限のコストで実装できる
元々これが目的で構築したので当たり前と言えば当たり前ですが知識ゼロからでも1週間程で構築できてしまう為かなり入りやすいと思います。知識があれば1日で構築できてしまうかもしれません!!
- システムの説明が容易
特に導入初期頃はどういうシステムなのか? という質問が多く、説明する機会がかなり多いです。説明資料作るにしても複雑なシステムを理解して貰える資料を作るのは一苦労です。他の人に理解して貰いやすいシステムという意味でもメリットがありました。
【デメリット】
- 安定性の不安
冗長化ができていないという点です。何か障害があったときは実行されない為、データがないと業務が全くできないという現場には不向きなシステムになっています。対してDigdag Server×Fargateの場合は冗長化できている為安定性はかなり上がりました。
- 運用面の不安
実行ログはEC2内に吐き出しを行っていましたがsshしないと見れない状況だった為、エラーチェックは基本Slack通知で行っていました。実行されているかの確認もSlack通知になる為、成功通知もSlackで確認することになります。Digdag serverになってからはDigdag UIで実行ステータスやログを確認できるようになったのでかなり作業がしやすくなりました。
実装方法
Dockerfile
FROM openjdk:8-jre-alpine
RUN apk add --no-cache libc6-compat libc-dev python3 python3-dev coreutils tzdata curl && \
cp /usr/share/zoneinfo/Asia/Tokyo /etc/localtime && \
echo "Asia/Tokyo" > /etc/timezone
# pipをupgradeする
RUN pip3 install --upgrade pip
# pythonのモジュールをインストールする
RUN pip3 install pytz mysql-connector-python google-cloud-bigquery python-dateutil boto3
# py>: でpython3が使えるようにシンボリックリンクさせる
RUN ln -s /usr/bin/python3 /usr/bin/python
# digdag 本体をインストールする
RUN curl -o /bin/digdag --create-dirs -L "https://dl.digdag.io/digdag-latest" \
&& chmod +x /bin/digdag
# Embulk 本体をインストールする
RUN wget -q https://dl.embulk.org/embulk-latest.jar -O /bin/embulk \
&& chmod +x /bin/embulk
# 使いたいプラグインを入れる(embulk-input-mysqlなど)
RUN /bin/embulk gem install embulk-input-mysql embulk-output-bigquery
# 実行ファイルのコピー
COPY ${プロジェクト名}/ /tmp/${プロジェクト名}/
RUN chmod -R +x /tmp/${プロジェクト名}/shell/
# 環境変数設定(必要に応じてデータベースの接続情報を環境変数に格納する)
ENV GOOGLE_APPLICATION_CREDENTIALS "/tmp/${プロジェクト名}/key/project-id.json"
今回はMySQLからBigQueryへの同期をご紹介します。その為に embulk-input-mysql と embulk-output-bigquery を インストールします。必要に応じてインストールするプラグインを変更してください。
定期実行
crontabで任意の時間に以下のようなコマンドを実行させます。
sudo docker run -w /tmp -i /tmp/${PROJECT名}/shell/run_hoge.sh
run_hoge.sh
#!/bin/sh
digdag run /tmp/${PROJECT名}/src/dig/run_hoge.dig --session daily --project ${PROJECT名}/src/dig
--project でファイルのあるフォルダを指定するのが肝だったりします。
digdag + embulk

| 役割 | 説明 |
|---|---|
| 取得テーブルの制御 | embulk実行時のSELECT・FROM・WHEREの制御する |
| embulkの制御 | どのDBからどのDBにデータを移すか(どのプラグインを使うか) |
| データの同期 | embulkの実行 |
フォルダ構成
リポジトリ ├── crontab ├── Dockerfile ├── プロジェクト名 │ ├── shell │ │ ├── run_hoge.sh │ ├── key │ ├── project-id.json(BigQueryのアクセスキーjson) │ └── src │ ├── dig │ │ ├── run_hoge.dig (取得テーブル制御用) │ │ ├── hoge.dig (embulkの制御用) │ │ ├── py_arg │ │ │ ├── source_table.py │ │ ├── slack │ │ │ ├── failed-to-sync-table-template.yml (失敗通知用) │ │ │ ├── success-to-sync-table-template.yml (成功通知用) │ ├── embulk │ │ ├── hoge.yml.liquid (データの同期) │ └── source_table │ └── hoge.json
取得テーブルの制御
- run_hoge.dig
timezone: Asia/Tokyo
# Slack通知のためのプラグインの読み込み
_export:
plugin:
repositories:
- https://jitpack.io
dependencies:
- com.github.szyn:digdag-slack:0.1.4
webhook_url: https://hooks.slack.com/services/XXX/XXX/XXX
workflow_name: run_hoge_dig
+table_list:
py>: py_arg.source_table.set_table
filename: "../source_table/hoge.json"
+for:
for_each>:
data: ${source_table}
_parallel: false
_do:
call>: hoge.dig
for_each> 取得したいテーブルをfor_eachで切り替える。
_parallel: false スケーリングができていない為、並列処理は無効にします。
import digdag
import json
def set_table(filename):
f = open(filename, 'r')
json_data = json.load(f)
# 環境変数に設定
digdag.env.store({"source_table": json_data})
[
{
"table": "users",
"out_table": "users",
"dataset": "hoge",
"select": "id, name"
},
{
"table": "purchases",
"out_table": "purchases",
"dataset": "hoge",
"select": "id, user_id, purchase_datetime, price"
}
]
| key | 役割 | 必須 |
|---|---|---|
| table | 取得テーブル名 | yes |
| out_table | 挿入テーブル名 | yes |
| dataset | BigQueryのデータセット名 | yes |
| select | 取得したいカラム | yes |
| where | 取得時のwhere句 | no |
embulkの制御
- hoge.dig
+run_embulk:
_retry: 2
_export:
HOST: ${host}
USER: ${user}
PASSWORD: ${password}
DATABASE: ${database}
DESTINATION_DATESET: ${data.dataset}
EMBULK_INPUT_TABLE: ${data.table}
EMBULK_OUTPUT_TABLE: ${data.out_table}
SELECT: ${data.select}
WHERE: "${ typeof(data.where) !== 'undefined' ? data.where : '1 = 1' }"
sh>: TZ=JST embulk run ../embulk/hoge.yml.liquid
# エラー通知
_error:
slack>: slack/failed-to-sync-table-template.yml
# 成功通知
+success:
slack>: slack/success-to-sync-table-template.yml
typeof(data.where) !== 'undefined' ? data.where : '1 = 1' は苦肉の策だったのですがembulkでwhereを指定する場合、''(空文字列)だとエラーになるので'1 = 1'を指定するようにしています。
TZ= の部分は取得DBのタイムゾーンを指定します。設定していない場合は実行環境のタイムゾーンが適応されるので注意が必要です。もしタイムゾーン指定が間違っていた場合はtimestamp型のカラムは時間がずれてBigQuery側に挿入されてしまいます。
slack/failed-to-sync-table-template.ymlとslack/success-to-sync-table-template.ymlは digdag-slackというプラグインに関係しますのでszyn/digdag-slack のREADMEをご参照ください。
データの同期
- hoge.yml.liquid
in:
type: mysql
host: {{env.HOST}}
user: {{env.USER}}
password: {{env.PASSWORD}}
database: {{env.DATABASE}}
table: {{env.EMBULK_INPUT_TABLE}}
select: {{env.SELECT}}
where: {{env.WHERE}}
out:
type: bigquery
mode: [append or replase]
path_prefix: /tmp/
file_ext: .csv.gz
source_format: CSV
project: hoge
dataset: {{env.DESTINATION_DATESET}}
location: location
table: {{env.EMBULK_OUTPUT_TABLE}}
auto_create_table: true
formatter: {type: csv, charset: UTF-8, delimiter: ",", header_line: false}
allow_quoted_newlines: TRUE
encoders:
- {type: gzip}
まとめ
今回は分析基盤の初期運用について紹介しました。流行りのdigdagを使おうと決めてからかなりの道のりがありましたが、初期運用の頃から重宝しているワークフロー管理ツールです。分析基盤をこれから作りたいという方は是非試して頂けると嬉しいです。
【データ分析基盤構築】digdag+embulkをFargate運用

初めまして、ベガコーポレーション データ戦略部 分析基盤エンジニア 新卒3年目の武本です。分析基盤の構築をメインに担当しています。digdag+embulkでデータを同期するツールを開発しFargateでHA構成にしたのでご紹介したいと思います。
入社した当初の分析基盤の状況
分析基盤をご紹介する前に開発前の状況についてお話しします。
かれこれ2年前の話になりますが私が入社した頃にBigQueryを導入しようという話になっていました。
分析に必要なデータを一元管理し、クエリを高速に実行させ、ストレスなく分析業務ができる環境を作るというのが一つの目標でした。
とりあえず必要になったのがBigQueryでデータを一元管理する為のシステム。つまり分析基盤の構築です。
分析基盤構築の開発に当たって調べているとdigdag + embulkでデータを同期させるという事例が多く、弊社もdigdag + embulkで分析基盤を構築しようという話になりました。
最初に作った分析基盤のシステム
Digdag Serverというリッチなシステムがあることは知っていたのですが最速で構築する為に digdag + embulk + cronでシステムを稼働させました。詳しくは後日初期運用編の記事を公開します。
初期運用システムの課題点
- 冗長化ができていない
- オートスケーリングに対応できていない
- ログ管理ができていない
- 実行ステータスの確認がslack通知
システムが止まればデータが同期できない状況。将来同期するデータが増えるとパンクする。ログや実行ステータスなどの運用面でも不安。といくつか課題が残りました。
そこでdigdagをserver化し、Fargateで運用しようという話になりました。
digdag・embulkとは
本題に入る前に直々出ているdigdagとembulkについて説明します。
digdagとは
digdagとはワークフローエンジンのソフトウェアです。複数個のタスクのパイプラインを構築し、実行やスケジューリングを行うことができます。Digdag UIでは実行ステータスやログを確認することができる為監視もしやすいツールになっています。今回はDigdag Serverの主な機能・実装方法についてご紹介します。
embulkとは
embulkとはデータ転送に特化したマルチソースバルクデータローダーです。RDSからBigQuery、S3からRDSなどのデータ転送をプラグインを用いて行うことができます。digdagから実行することによりデータ取得とデータ加工をワークフローに則って行うことができます。
Fargateで運用するメリット・デメリット
一般的に言われているFargateのメリット・デメリットに準じますが、Digdag Serverと組み合わせた場合、どのように影響するのか説明します。
【メリット】
・冗長化しやすい
必要なタスク数を設定しておけば、もし落ちたとしても自動で再起動してくれるので運用が楽。
・リソースの拡張・縮小がしやすい
連携するデータ量が増えて処理が重くなればタスク定義でスペックをあげれば良いだけなので管理が楽
一回で移動させるデータ量が少ないが連携するテーブルが多いという場合はサービスのタスク数を増やしてあげるだけで対応できる。
・EC2を管理しなくていい
EC2の場合OSやミドルウェアなどの構築や設定操作が必要だが省くことができ、簡易的に構築・管理することが可能。
・Fargate SPOTで運用
Digdag Serverはフロー管理している為処理の途中で落ちたとしても自動で再実行してくれる。
SPOTとの相性も良く費用を抑えて運用ができている。
【デメリット】
・パブリックIPの固定割り当てができない
Digdag UIの閲覧やdigdagのクライアントモードコマンドを実行する際にroute53とALBを噛ませる必要性がある。
・sshやdocker execが使えない
Digdag Server構築時は実行ログを吐き出させて、その実行ログを元に開発することになる。パラメータストア経由で設定する環境変数のチェックなどの確認が面倒。
デメリットは開発面での話で運用面でのデメリットはほぼないという印象です。
【本題】Digdag Server構築とFargate運用
構成図

Digdag Server構築
Digdag Server構築に必要な要素についてお話します。
構成
| 役割 | |
|---|---|
| Fargate | サービスの起動やスケーリングを行う |
| rest server | Digdag UI と API Server |
| work server | digdag タスク実行用Server |
| Aurora(postgres) | フロー定義と実行タスクの保存 |
| Amazon S3 | タスク実行ログの保存 |
| 各種DB | 同期元 |
| BigQuery | 同期先(データレイク & データウェアハウス) |
| Looker | BIツール |
rest serverとwork serverの違い
rest serverは Digdag UIとクライアントコマンド受付用です。実行するワークフローをrest serverで登録しwork serverで実行させるという流れになります。rest serverは重たい処理を行わない為リソースは少なくても問題ありません。ECSのタスク定義で調整しつつ環境に合う設定を行ってください。
実装上での違いは指定するオプションとconfigファイルです。
rest
# --disable-executor-loop: Workflow executorを無効にする # --disable-local-agent: Agentを無効にする # --disable-scheduler: Schedule Executorを無効にする digdag server --disable-executor-loop --disable-local-agent --disable-scheduler --config /etc/digdag/server-rest.properties
work
digdag server --config /etc/digdag/server-work.propertie
configファイルに関しては最後の方で説明します。
定期実行(Scheduling workflow)
定期実行はdigファイルの先頭に以下の内容を書くだけで設定できます。
timezone: Asia/Tokyo schedule: daily>: 07:00:00
詳しくはScheduling workflowをご覧ください。
タスク管理(PostgreSQL)
digファイルやタスクキューなどはPostgreSQLに保存します。Amazon AuroraのPostgreSQLを採用しています。
以下の設定をdigdagのconfigファイルに記入。<POSTGRES_USER>系はそのまま記入してください。パラメータストアに登録し、sedコマンドで上書きします。
database.type = postgresql database.user = <POSTGRES_USER> database.password = <POSTGRES_PASSWORD> database.host = <POSTGRES_HOST> database.port = <POSTGRES_PORT> database.database = <POSTGRES_DATABASE> database.maximumPoolSize=32
ログ管理(S3)
以下の設定をdigdagのconfigファイルに記入
log-server.type = s3 log-server.s3.endpoint = <S3_ENDPOINT> log-server.s3.bucket = <S3_BUCKET> log-server.s3.path = <S3_PATH> log-server.s3.direct_download=false
指定したPATHにログが出力され、Digdag UI上でログの確認できるようになります。

オートスケーリング(Fargate)
データ連携する時間だけworkのタスク数を増やすという運用をしています。
具体的にはdigdagから以下のシェルスクリプトを実行してタスク数を変更します。
#!/bin/sh
# AutoScaling($1は引数。必要なタスク数をdigdag側で指定)
aws ecs update-service \
--cluster hoge \
--service digdag_work \
--desired-count $1
# スケーリングされるまで待機
aws ecs wait services-stable \
--cluster hoge \
--services digdag_work
# タスク数取得
task=$(aws ecs describe-services \
--cluster hoge \
--services digdag_work \
| jq '.services[].runningCount')
message="task数: ${task}"
#タスク数出力
echo $message
if test $task -ne $1 ; then
exit 1
fi
digdag側では _parallelをtrueにすることで並列処理を行い、スケーリングの効果を発揮させます。
# スケールアウト
+scaling:
sh>: shell/autoscaling.sh 5
_error:
_export:
message: "Failed Scale Out"
slack>: slack/failed-to-sync.yml
# テーブル取得
+sync:
for_each>:
data: ${source_table} # json形式の取得時の情報(select, from, whereなど)
_parallel: true
_do:
call>: run_embulk.dig
まだ試してはいませんが digdag 0.10.0で 並列化する数を制限できるようになったみたいなのでスケーリングと組み合わせると綺麗な実装になるかもしれません。 Release 0.10.0
digdag secrets
embulkでアクセスするDBの接続情報はdigdag secrets で管理します。
以下の設定をdigdagのconfigファイルに記入
digdag.secret-encryption-key = <SECRET_ENCRYPTION_KEY>
詳しくはsecret-encryption-key をご覧ください。
続いて、接続するDBの情報をjson形式で保存します。
gcp.credentialは必要に応じて用意してください。
{
"host": "xxxxxxxx",
"user": "xxxxxxxx",
"password": "xxxxxxxx",
"db": "xxxxxxxxx"
}
以下のコマンドを実行してdigdag serverに登録します。
# secretsキーデプロイ
digdag secrets --project ${PROJECT} --set @${DIR}/secrets.json -e ${URL}
# gcp.credential設定
digdag secrets --project ${PROJECT} --set gcp.credential=@credential.json -e ${URL}
-eオプションでURLを指定して登録できます。rest serverのURLを指定してください。
ログイン認証
ログイン認証はbasic認証で行います。アクセスするのはrest serverなのでrest serverのみ設定を行います。
以下の設定をrest用のconfigファイルに記入
server.authenticator-class = io.digdag.standards.auth.basic.BasicAuthenticator basicauth.username = <USERNAME> basicauth.password = <PASSWORD> basicauth.admin = true
Digdag UIの認証設定
ログイン画面は機能していない為、Google Chrome のプラグイン simple-modify-headers を利用します。

クライアントコマンドの認証設定
以下のコマンドで設定します。
export DIGDAG_CONFIG=client.http.headers.Authorization="Basic {hoge}"
{hoge} の取得方法
echo -n '{username}:{password}' | openssl base64
{username}と{password}はそれぞれ basicauth.username と basicauth.password です。
コンテナ起動時のコマンド
設定はECSのタスク定義にて行います。
コンテナ起動時に以下のことを行います。
- configファイルの上書き
ログイン認証・PostgreSQL・S3などのユーザー名、パスワードはAWSのパラメータストアで管理する。
パラメータストアの値を反映させる為、sedコマンドでconfigファイルを上書きする。 - PostgreSQLの起動
- Digdag Serverの起動
configファイルと実行オプションでrestとworkを切り分ける。
rest server起動用のシェルスプリクト
#!/bin/sh
sed -i -e "s/<USERNAME>/${USERNAME}/" \
-e "s/<PASSWORD>/${PASSWORD}/" \
-e "s/<POSTGRES_USER>/${POSTGRES_USER}/" \
-e "s/<POSTGRES_PASSWORD>/${POSTGRES_PASSWORD}/" \
-e "s/<POSTGRES_HOST>/${POSTGRES_HOST}/" \
-e "s/<POSTGRES_PORT>/${POSTGRES_PORT}/" \
-e "s/<POSTGRES_DATABASE>/${POSTGRES_DATABASE}/" \
-e "s/<S3_ENDPOINT>/${S3_ENDPOINT}/" \
-e "s/<S3_BUCKET>/${S3_BUCKET}/" \
-e "s~<S3_PATH>~${S3_PATH}~" \
-e "s/<SECRET_ENCRYPTION_KEY>/${SECRET_ENCRYPTION_KEY}/" /etc/digdag/server-rest.properties
# rendering pgpass file
echo "$POSTGRES_HOST:$POSTGRES_PORT:$POSTGRES_DATABASE:$POSTGRES_USER:$POSTGRES_PASSWORD" > ~/.pgpass
chmod 600 ~/.pgpass
# postgresが起動するまで待機
COUNT=0
until psql -h "$POSTGRES_HOST" -U "$POSTGRES_USER" -p "$POSTGRES_PORT" -d "$POSTGRES_DATABASE" -c '\l' || test $COUNT -gt 10 ; do
let COUNT++
sleep 10
done
# Digdag Server起動
# --disable-executor-loop: Workflow executorを無効にする
# --disable-local-agent: Agentを無効にする
# --disable-scheduler: Schedule Executorを無効にする
digdag server --disable-executor-loop --disable-local-agent --disable-scheduler --config /etc/digdag/server-rest.properties
work用もシェルスプリクトを用意するが、異なるのはDigdag Server起動のオプションとログイン認証の部分のみ。 Digdag ServerのオプションについてはCommand referenceをご覧ください。
まとめ
今回はDigdag ServerをFargateで動かす方法についてご紹介しました。FargateでDigdag Serverを動かしてみるという記事は少なく手探り状態で開発しましたが、期待以上のシステムになったのではないのかなと思っています。digdag導入初期の運用やデータの同期方法については別の記事でご紹介したいと考えています。
技術書典5に参加しました
こんにちは。R&Dグループ エンジニアのpondayです。
2018/10/08に開催された技術書典5に参加してきました。今回はその参加レポートを記事にします。
技術書典とは?
その名前の通り、『技術書の祭典』です。
有志が執筆した技術系同人誌を持ち寄って頒布するイベントで、フロントエンド、バックエンド、アプリ、ネットワーク、ハードウェア、電子工作など、幅広いジャンルの技術書が集まります。
商業誌ではなかなかお目に書かれないすごくニッチな技術の本から、注目度は高まってきているもののまだまだ日本語情報が出揃っていない技術の入門書、実際にサービス利用してみての知見など、最新の生きた知識に触れることができるのが最大の魅力です。
2016年6月の初開催から半年に1回のペースで開催されていて、今回が5回目の開催でした。
ベガコーポレーションはサークル『VEGA Tech』として、社内のエンジニア有志が執筆した技術書4冊を頒布してきました。
参加の経緯
今回のサークル参加は自分から提案したものです。
ベガコーポレーションとしては今回が初参加でしたが、実は私自身は技術書典2の頃から継続してサークル参加していて、当然今回も参加する気満々でした。 参加にあたっては個人参加も検討していたのですが、募集がかかる直前にベガコーポレーションにジョインしたので「せっかくなら」と話を持ちかけたらノリノリだったこともあり、会社として参加することになりました。
参加メンバー
執筆に参加したのは以下の3名でした。
- foxtrackjp
- mrtk
- ponday
頒布したもの
Amazon Connect入門
著:foxtrackjp
AWSに何かと詳しいfoxtrackjpさんらしく、まだ東京リージョンにすら来ていない新サービス「Amazon Connect」の解説本です。AWS上でコールセンター業務の一部が自動化できるという一風変わったサービスで、機械音声による自動応答や、ユーザー入力に応じた返答のカスタマイズなど、基本的な使い方を画面キャプチャを交えて解説しています。
blenderによる輪郭線の表現
著:mrtk
3Dエンジニアmrtkさんからはblender本。2Dの表現で重要な役割を担う輪郭線を、3Dの世界に持ち込むための手法を検討しています。私はblenderには詳しくないのですが、画像も多く結果がわかりやすくまとまっているのではないかと思いました。
速習Elixir
著:ponday
弊社で技術検証を行っているプログラミング言語『Elixir』の入門本です。入門編ということでマクロのような高度な機能は省いて基本的な構文のみに絞って解説しています。社内でも参考資料として使えれば良いなという思いで執筆しました。
Web Components First Book
著:ponday
タイトルの通り『Web Components』というWebのAPIを解説した本になっています。上の3冊と違って社内では利用していない技術についての書籍なのですが、「フロントエンドネタも欲しい!」という個人的な意見で執筆しました。
執筆環境
原稿を書く、と言ってもAdobe InDesignのようなDTPソフトを使いこなせるメンバーはいませんでしたし、そもそも各人に環境構築してもらうのも面倒です。できることならMarkdownで済ませたいところでした。
技術書典界隈ではRe:VIEWという書籍執筆用のテキストフォーマットが良く知られていて、Markdown → Re:VIEW → PDFという変換を行ってくれるDockerイメージも主催メンバーの方から公開されています。実際、結構な数のサークルさんがこのDockerイメージを使っている印象です。
一方、最近少しずつですがCSS組版でPDFを生成しているサークルさんも増えてきています。これは、MarkdownからHTMLに変換してCSSで本のようなフォーマットに装飾する手法で、作り方次第では自由度の高いレイアウトが組めるのが魅力です。
page-break-after: always;
のような、Web制作では使わないCSSが知れたりもします。
今回は(面白そうだったので)Markdown → PDF変換を行うプログラムを自前で開発して、CSS組版に挑戦してみました。今回頒布した本は全てこのプログラムを利用して生成したものです。
内部的な実装で言うと、
markdown-itでMarkdown → HTMLに変換- ↑のHTMLはヘッダ要素などがないので、
mustacheフォーマットのHTMLテンプレートを別途用意して生成したHTMLを埋め込み - 生成したHTMLを
puppeteerで開き、印刷機能を利用してPDF化
という感じで実装しています(画像周りの処理や生成したHTMLに対するDOM操作なども行っていますが、その辺りは割愛します)。
VSCode拡張のmarkdown-pdfを参考に開発しました。
技術的な課題も多く悩まされたこともあったものの、執筆の気分転換に機能拡充する、という切り替えができて良い気分転換になったかなと思っています。時間的な制約もあり、実装できていない機能や足りない機能だらけではありますが次回また改良して使いたいところです。
当日の様子
当日は私と、初参加となるmrtkさんで現地参加しました。
前回までは秋葉原UDXで開催されていたのですが、キャパシティ的に限界ということで今回から会場を池袋サンシャインシティに移しての開催となりました。会場の床面積が3倍程度になった反面、サークル数は2倍程度に抑えられていたようで、通路は前回までに比べると明らかに広くなったな、という印象でした。
それでも開場してみるとその通路が人で埋まってしまい身動きが取りづらい場面すらあり、どんどん技術書典に注目している人が増えていることを実感しました。一技術書典好きとして嬉しい限りです。最終的に、サークル参加まで含めた総来場者数は10,000人を超えた(!)そうです。
我々はと言うと、サークル側で参加しているとはいえせっかく現地に行っているからには他のサークルの本も見たい!ということで、交代で店番をしながらもう一方が買い物に行く、という感じで回していました。買い物を終えて帰ってくるたびに満足そうに本を抱えているmrtkさんが印象的でした(笑)
私達のブースでも足を止めてくださる方もたくさんいらっしゃいました。お越しくださった方々、ありがとうございました!
反省点
社内メンバーを巻き込んでの参加は初めてだったので、反省点もたくさんありました。中でもこれからの課題だと感じたのは「"執筆"に対して感じているハードルの高さ」です。
今回声を掛けたものの断られてしまった社内のメンバーからも、
- 忙しい
- 本を書けるほどの知識がない
- 本にできるようなネタが準備できない
- 大変そう
と言った声がよく聞かれました。
1番はサービスのローンチと時期がかぶってしまった面があるので仕方がないかなと思います。
2、3 番はやはり「書籍」や「執筆」という言葉に対するハードルがあるのかなと感じました。「高度な内容でないといけないんじゃないか。」「こんな基本的な内容の本を書いてもみんな知ってることじゃないのか。」という感じでしょうか。実際に書いて頒布してみると「意外と書ける」し、「開発を通して得た知識、ノウハウが役に立つ人も一定数いる。」ということが実感としてあるのですが、このあたりのハードルを取り払えなかったのが自分の反省すべきところかなと思います。
「大変そう」という意見については実際それなりに大変なので否定できないです(笑)ただそれでも毎回本を執筆して参加を続けているのは、現地でその大変さ以上の楽しさを体感しているからなので、そのあたりも上手く伝えていけるようになりたいですね。
その他、
- スケジュール管理
- 表紙やDLカードのデザインまわり
- 当日の売り方や役割分担
などなど、諸々の反省点もありましたが、次回以降改善していきます。
技術書典6に向けて
当然、次回も参加したいと思っています。
今回は多忙で執筆に参加できなかったものの、次回参加に向けて意欲を見せてくれているメンバーも出てきているので、今回の反省を活かしつつ取り組みたいと思います。
iOSDC JAPAN 2018
iOSアプリエンジニアの主計です。
今年も福岡からiOSDCに参加してきました。
去年もとても素晴らしいカンファレンスでしたが今年は更にパワーアップしているように感じました。iOSDCはコミュニケーションの場であり講義ではなく双方向コミュニケーションのカンファレンスとの説明が冒頭にあったのですが、それが実感できるカンファレンスだったと思います。
私自身いろんな方とコミュニケーションもとることができ、とても楽しむことができました。
印象に残ったセッション
どのセッションも興味深い内容でしたが、すべては紹介できないのでいくつか印象に残ったセッションを紹介致します。
MicroViewControllerで無限にスケールするiOS開発
www.icloud.com
今回のセッションのなかで一番聞きたかったセッションです。20人での開発もできるように画面を多数のViewControllerにしているとのことでした。
また、初期化の扱いやすさからInterfaceBuilderはStoryboardではなくXibを使うことでした。
GitHubでも公開されているのでコードリーディングしていきたい💪
github.com
「QRコード読み取り?楽勝ですよ😙」=>「AVFoundationを信じたおれがバカだった😇」
speakerdeck.com QRコードには連結機能がありAVFoundationでの読み取りについてのセッションでした。QRコード活用の仕方しだいでとても便利なので扱う際には読んでおくといいと思います。
Depth in Depth
www.slideshare.net 深度情報を使って人物の切り抜きなどのデモをみることが出来ました。制約もありますが、モバイルで簡単に切り抜きが出来れば役に立ちそうです。
諸事情により9/2(最終日)に参加できなかったので9/1までの中から紹介させていただきました。 後日、ビデオが公開されると思うので見れなかったセッションも含めてみていきたいと思います。
iOSDCリジェクトコン
iOSDC JAPAN 2018 は終わってしまいましたが、リジェクトコンが9/18と9/20日にあります。
また面白い企画もありますのでご応募お待ちしております。
iosdcrc.firebaseapp.com
今年は福岡にサテライト会場を用意していますので福岡の方も是非参加お願いします。
東京
iosdc-reject-conference.connpass.com iosdc-reject-conference.connpass.com
福岡(サテライト)
iosdc-reject-conference.connpass.com iosdc-reject-conference.connpass.com
来年はcfpだしてスピーカーとして参加出来るように頑張りたいと思います!
iOSネイティブコードから構造体をUnityに渡す
ベガコーポレーションでエンジニアをやっているStellarBiblosです。 初回からかなりニッチな所ですが、これに関しての情報があまり無いようで、折角ですから記事にしてみました。
構造体
まずは各々の方で構造体を宣言しますが、変数の宣言順序が異なると正しく渡せません。
新規で作成している場合には考慮しなくていいと思いますが32bitサポートの場合バイト長が違ったりするため注意です。
また、C#だとboolはデフォルトで4バイトに対してC++は1バイトなため[MarshalAs( UnmanagedType.U1)]で明示的に1バイトと宣言しなければダメです。
その後3バイト長のchar/stringを用いてパディングしておいた方がいいと思います。
そうでなくても末尾が余っている場合はパディングを推奨します。
[StructLayout(LayoutKind.Sequential, CharSet = CharSet.Ansi)] public struct Model { [MarshalAs(UnmanagedType.LPStr)]public string name; [MarshalAs(UnmanagedType.I4)]public int index; [MarshalAs(UnmanagedType.R4)]public float posX; [MarshalAs(UnmanagedType.R4)]public float posY; [MarshalAs(UnmanagedType.R4)]public float posZ; }
struct Model_t { const char *name; int index; float posX; float posY; float posZ; };
データ受け渡し
正しく構造体を作れていれば構造体のバイト長が一致します。 そのため構造体サイズ分アロケートしたポインタに対してmemcpyすればズレなくデータが取得できます。
class Reciever : MonoBehaviour { [DllImport("__Internal")] static extern void getModelStruct(IntPtr ptr); [DllImport("__Internal")] static extern void setModelStruct(IntPtr ptr); Model getModelFromNative() { var model = new Model(); var ptr = IntPtr.Zero; try { System.Runtime.CompilerServices.RuntimeHelpers.PrepareConstrainedRegions(); try {} finally { ptr = Marshal.AllocCoTaskMem(Marshal.SizeOf(typeof(Model))); } GetFurnitureStruct(ptr); model = (Model)Marshal.PtrToStructure(ptr, typeof(Model)); } finally { if(ptr != IntPtr.Zero) Marshal.FreeCoTaskMem(ptr); } return model; } void setModelFromNative(Model model) { var ptr = IntPtr.Zero; try { System.Runtime.CompilerServices.RuntimeHelpers.PrepareConstrainedRegions(); try {} finally { ptr = Marshal.AllocCoTaskMem(Marshal.SizeOf(typeof(Model))); } Marshal.StructureToPtr(ptr, model, false); setModelStruct(ptr); } finally { if(ptr != IntPtr.Zero) Marshal.FreeCoTaskMem(ptr); } } }
Model_t myModel = *new Model_t { "Vega", 0, 0.0, 1.0, 1.2 };
extern "C" void getModelStruct(Model_t *model_t) {
memcpy(model_t, &myModel, sizeof(Model));
}
extern "C" void setModelStruct(Model_t *model_t) {
memcpy(&myModel, model_t, sizeof(Model));
}
おまけ
配列も取れます。 予め何らかの方法で配列長を知る必要がある為完璧な実装ではないです。
class ArrayReciever : MonoBehaviour { [DllImport("__Internal")] static extern void getModelStructArray(IntPtr ptr); Model[] getModeArraylFromNative(int length) { var models = new Model[length]; var ptr = IntPtr.Zero; Int64 arrPtr = 0; try { System.Runtime.CompilerServices.RuntimeHelpers.PrepareConstrainedRegions(); try {} finally { ptr = Marshal.AllocCoTaskMem(Marshal.SizeOf(typeof(Model)) * length); } arrPtr = (Int64)ptr; getModelStructArray(ptr); for(var i=0; i<length; i++) { models[i] = (Model)Marshal.PtrToStrucure((IntPtr)arrPtr, typeof(Model)); arrPtr += (Int64)Marshal.SizeOf(typeof(Model)); } } finally { if(ptr != IntPtr.Zero) Marshal.FreeCoTaskMem(ptr); } return models; } }
Model_t myModels[3]; extern "C" void getModelStructArray(Model_t *models_t) { memcpy(models_t, &myModels, sizeof(myModels)); }
インターンで内定者さんがやってきた。
こんにちは。
ベガコーポレーション所属エンジニアの田中です。
今回は、インターンで新卒の内定者の方が来社されましたのでその内容について紹介させていただきます。
内定者さんには、弊社のデータ分析で使用しているSAP Predictive Analytics(以後SAP PA)を使って、電力予測とクラス分けの2つの課題に挑戦していただきました。インターン期間は2018年7月17日〜27日の約2週間で、成果発表を含めた課題解決を行っていただきました。
この記事の構成は、
§1. 電力予測
§2. クラス分類
§3. インタビュー
§4. 最後に
となっています。§1, 2が技術的な内容で、§3では内定者さんにインターンの感想などのインタビューを行ったものを掲載しています。そして、最後§4に総括・コメントを書いています。
§1. 電力予測
このセクションでは、SAP PAを用いた電力予測について紹介します。SAP PAの詳細については、以前のブログに記載されておりますので、ご興味のある方は参照していただければと思います。
インターン課題として、内定者さんにはデータの収集・整形からSAP PAを用いた予測モデルの構築までの一連の行程を行っていただきました。その中で、予測精度を上げるためにどのようなデータを与えれば良いかという点を内定者さん自身で考察していただきました。
学習データの収集では、電力会社が公開している電力量などの数値と該当地域の気候データの取得を行ってもらいました。これらデータを使って、SAP PAによる予測モデルを作成するためには目的変数と説明変数を設定する必要があります*1 。特に、目的変数として何を与えれば、予測制度が上がるのか?を考えることが重要な作業となります。加えて、与える説明変数の期間についても調整してもらいました。ちなみに収集・整形したデータを学習データと評価データに上手く分割することで予測モデルの汎化能力を上げることも内定者さんに行っていただきました *2。 これら地道な調整の結果、今回は全てのモデル作成で「学習データ:2012年〜2017年, 評価データ:2018年〜予測日」の分割期間を採用しました。
今回の予測対象は、2018年7月1日〜17日の期間での日毎の最大電力となっています。まずは、説明変数として気温を与えたものの中で、2パターンの結果を示します。 2パターンとは、それぞれ説明変数の期間を対象日から過去1週間分と過去1ヶ月間分に設定している場合に分けています。また、予測値を評価する指標としては、Root Mean Square Error (RMSE)を使用しました。RMSEは、予測と実測との差を表している値で、ゼロに近いほど予測精度が高いことを意味します。
それでは、最大電力の予測結果を見ていきます。
1)説明変数:対象日から1週間前の気温

RMSE
SAP PA : 117.1 電力会社: 68.50
2)説明変数:対象日から1ヶ月前の気温

RMSE
SAP PA : 112.7 電力会社: 68.50
上記2つの結果から、説明変数として気温だけを与えた場合は、説明変数の期間を調整することで僅かに予測精度が上がったものの、残念ながら2パターンともに電力会社の予想精度を大きく下回ってしまう結果となりました。
次に、昨年の同時期の電力を説明変数として与えたものを示します。
説明変数:対象日から1年前の前後3日分の電力

RMSE
SAP PA : 76.47 電力会社: 68.50
SAP PAの予測精度は大きく向上したものの電力会社の予測精度にはまだ及びません。
そこで、説明変数として、気温と昨年の電力を併用したモデル作成しました。
説明変数:当日の気温と前3日分の電力

RMSE
SAP PA : 36.15 電力会社: 68.50
結果としては、電力会社よりも高精度な予測値を出すことができました。しかし、今回の予測モデルでは気温の変動が大きい時期に対する予測精度が著しく悪化してしまう汎化性での欠点も見つかりました。このように、予測モデルの性能の観点では、以前に弊社エンジニアが作成したモデルには及びませんでしたが、内定者さんの新しい発想から多くの発見が生み出されました。
§2. クラス分類
次に、挑戦していただいた課題はクラス分類の問題となっています。特に、インターンではある2次元上のデータを2つのクラス(または3つのクラス)に分類する問題を解いていただきました。このクラス分け問題は、以下のように、2種類の値(+1またはー1)が分布しているデータを2色の領域に色分けする課題へと置き換えることができます。

この課題では、新卒エンジニアである私も同じ課題に挑戦し、どちらが上手く色分け出来るかの対決を行いました。 ちなみに私は、SAP PAとは別の手法としてTensorFlow(以後、TF)を用いたディープラーニングのアプローチから挑戦しました。

今回は、与えられた学習データに対して、どのような学習モデルをどのように構築するのかという点にフォーカスした課題となっています。それでは、さっそく3本勝負の結果を見ていきます。ちなみに、勝敗の判定基準は内定者さんの主観です。
第1問) 2クラスの分類(長方形)

僅差で私、田中の勝利!! 正直、微妙なところですが内定者さんに1勝を譲ってもらいました。
第2問) 3クラスの分類

私は2色にしか色分けできていないのに対して内定者さんは3クラスに分類できているので、完全に内定者さんの勝利。
第3問) 2クラスの分類(ロール)

何となく渦巻きを巻いているので私の勝利!! ということで3本勝負の結果は、内定者さん1勝、私2勝で何とか面目を保ちました。
最後に、第3問に特化したアルゴリズムを内定者さんが作成して下さったので、その色分け結果を示します。詳細は省きますが、それなりに上手く色分けできているように思います。

§3. インタビュー
最後に、内定者さんにインタビューした内容を一問一答形式でまとめました。私からの質問に対して、内定者さんが答えるというものです。
Q1. 今、大学ではどのようなことをしていますか?
A1. 大学ではRubyを使って教育用プログラミング言語Scratchを対象とした研究を行っています。また、ものづくり部でアプリ制作もしています。学外では小・中学生にRubyプログラミングを教える団体に所属しています。あとエンジニア主体のRubyの勉強会に参加したりもしています。
Q2. ベガの選考を受けようと思ったのは何故ですか?
A2. 福岡に知り合いが多い中で、ベガを知りました。福岡という土地柄と社員さんの雰囲気の良さに魅力を感じ選考を進めて来ました。東京の企業も何社か受けましたが、技術レベルの高さとユニークな強みのある会社であると感じたことが決め手となりました。
Q3. インターンを受けようと思ったのは何故ですか?
A3. 一番はベガの社員さんの雰囲気を知りたいと思ったからです。あと実業務に早く触れて実践的に技術力を身に付けていきたいと考えました。
Q4. インターンで技術的に大変だったことは何かありますか?
A4. 今までデータ分析をしたことがなかったので、予測モデルを作成することが大変でした。ただ、メンターさんに親切に教えていただいたので何とか形することができました。
Q5. インターンの雰囲気はどうでしたか?
A5. 社員さんの雰囲気がとても良かったです。質問しやすい環境で自分のアイディアなども聞いていただけて楽しく課題に挑戦できました。
Q6. なんとなくでも職場の雰囲気、業務のイメージはつかめましたか?
A6. 職場はキレイで家具も揃っていて雰囲気もとても良かったです。あとランチにも連れて行ってもらえて、いろいろ話ができてよかったです。業務の具体的な内容までは把握しきれてはいませんが、大まかなイメージはできたように思います。
§4. 最後に
今回のインターンでは、二週間という短い期間の中で試行錯誤をしながら、しっかりと成果発表までやりきった内定者さんを見て、『とても優秀な学生さんだな』という印象を受けました。このような優秀な学生さんが弊社に集まって来ている状況をとても嬉しく思いつつ、弊社のエンジニアとしては身の引き締まる思いです。来年度から一緒に働いていけることを楽しみにしています!!
try! Swift 2018
ベガコーポレーションのiOSアプリエンジニアの主計です。 だいぶ遅くなってしまいましたが、3月1日〜3月3日で行われたtry! Swift 2018というカンファレンスに参加してきましたので印象に残ったセッションなどを簡単にレポートしたいと思います。 www.tryswift.co
印象に残ったセッション
Swift によるアルゴリズムの可視化
このセッションは内容も良かったのですがデモのライブコーディングがすばらしかったです! デモではPlaygroudを活用してベジェ曲線の仕組みがわかりやすくコードに落とし込んでいてわかりやすかったです。 自分はまだまだ開発段階でのPlaygroundの活用がたりないなとも感じさせられました。
動画・スライド
www.youtube.com speakerdeck.com github.com
超解像+CoreML+Swiftを使ってアプリの画像データ転送量削減に挑戦する
CoreMLと聞くと解析やAIという先入観がありましたが、こんな活用法もあるのか!と気づかせてもらえました。 画像の転送量削減は画像を使っているサービスならどこにでもあてはまることですし、UXにも直結するので試してみたいなと感じました。
動画・スライド
www.youtube.com speakerdeck.com github.com
番外編(お昼休み)
ランチを食べ終わってスポンサーブースを歩いていると人だかりが。。。 Yahoo! Japanさんのブースでライブコーディングが行われていたので覗いてきました。 普段開発している様子を紹介してくださっていたようでしたので時間を忘れて見入ってしまいました。 簡単に概要をまとめると、
- ペアプログラミングでTDD
- 細かい粒度のToDoを元に1人がテストコードを記述
- テストが失敗ことを確認
- もう1人がテストが通るように実装
- テストが成功することを確認
- レビューしリファクタ
- ToDoにチェック
このような形で開発をしているとのことでした。 また、実装時にレビューは完了しているため、プルリクエストの際にはコードビューは行っていないみたいです。 テストコードのメソッド名を日本語で記述し、テストコードが仕様書になるように実装されていたのも面白かったので参考にしてみたいと感じました。
まとめ
国内外問わず素晴らしいセッションばかりでした。 海外のエンジニアと交流できたりできとても良いカンファレンスでした。 ただ、自分の英語力のなさに毎回落ち込みます。。。少しずつでも勉強しないといけないですね。。。 来年も必ず参加したいと思います。